The goal is to declutter and categorise my bookmarks collection to make it easier to navigate, and rediscover forgotten links. From my previous experience with LLMs and RAG (Retrieval Augmented Generation), it felt like this would be a good solution to the dynamic categorization problem.
I've gathered nearly a thousand bookmarks over the last years, initially they were well-organized, but eventually the list grew out of control, since I don't always have time to sort new ones.
Many of my bookmarks also serve as a "read later" reminder, a collection of interesting articles I want to reread, or couldn't fully read at the time.
Before and After Demo - Github Repo

Approach
You can find the code for this article on my GitHub repository.
-
Export your bookmarks to HTML using Chrome's built in feature. This also serves as a backup incase anything goes wrong.
-
Create a local headless chrome docker container by following the documentation here. You can also use your locally installed Chrome, you'll just need to enable the remote debugging port.
This provides you a HeadlessBrowser that can be controlled via a remote debugging port (default 9223). You can launch as many as you want across a docker swarm.
Self-hosted and similar to Browserless and Browserbase, but free. If you need help setting this up, reach out on LinkedIn or Telegram.
-
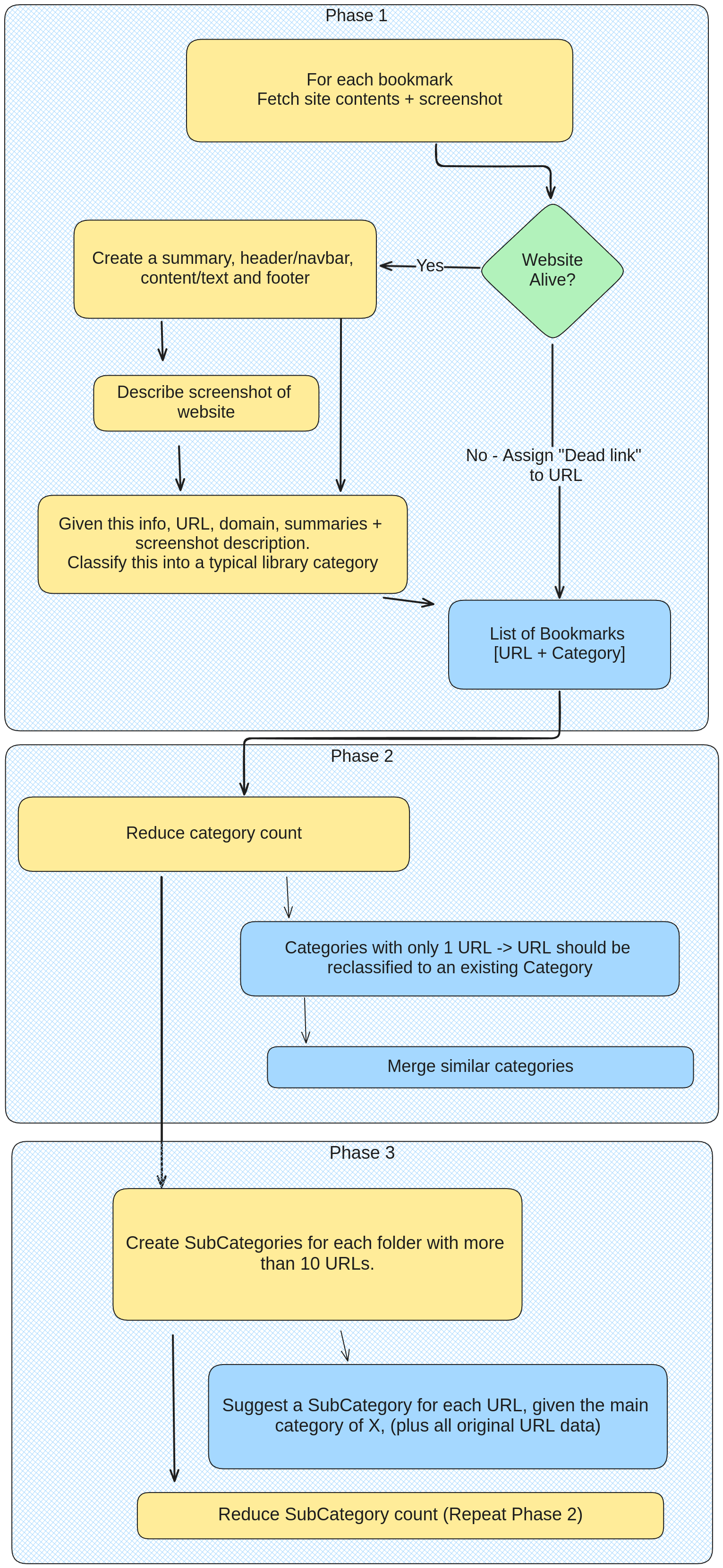
Run a Python script performing the following steps:
poetry run python main.py -f bookmarks_30_08_2024.html --chrome localhost:9223 --ollama localhost:11434 --model llama3.1:latest- Parse the exported HTML Bookmarks file to extract each bookmark.
- Use Playwright to navigate each URL and collect additional metadata (title, description, keywords). Using your local headless Chrome container as a browser.
- Save this metadata along with the URL for each bookmark in a JSON file. This will serve as a cache to avoid reprocessing URLs that have already been processed on reruns.
- Use a local LLM (I used llama3.1 to categorize bookmarks into meaningful categories (e.g., "Programming", "Personal Development", etc.). If a site is unreachable, 404, etc, classify it as "Dead". I used the Haystack AI framework for creating an LLM pipeline, and I'm running ollama locally, serving as my LLM backend for Haystack.
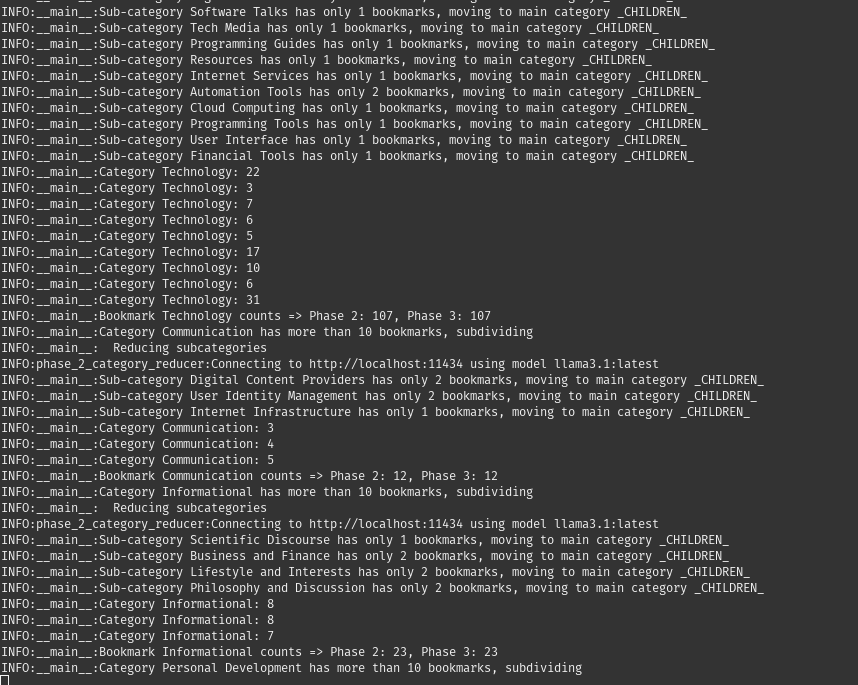
- Some AI classifications were very similar, e.g., Tech / Technology / Software. So I used another LLM pipeline to try and merge these categories.
- Some categories were still too crowded, e.g. Technology, which contained 50% of all my bookmarks. So I created another pipeline to further categorize these crowded categories into more fine-grained subcategories. (Similar to Step 4-5, but applied to specific categories)
- Export the categorized bookmarks back to HTML according to the Netscape Bookmark File Format


- Inside your browser's bookmark manager, delete all your existing bookmarks. Be sure that you still have your backup from Step 1!
- Import the generated HTML file from Step 3.7
Potential improvements:
- There are clearly still misclassifications, I think tweaking the prompt or gathering additional data from the website to pass to the LLM could improve this.
- The script could look at your browser history to enhance the categories, maybe a "daily" folder for frequently visited sites.
- I tried using a website screenshot as input as well to a multi-model LLM like llava-llama3, but this didnt yield any interesting results given the added complexity.
Thoughts:
I'm excited about LLM use cases in real world applications, especially LLM Agents used to automate simple repetitive tasks like this one. This will become an essential tool to master, it's clearly going to increase productivity. Much like the arrival of spreadsheets.
Keywords:
#AI #LLM #BookmarkManager #Bookmarks #Python #Playwright #HeadlessBrowser #Docker